

【Gatsby.js】コードを削減する「File System Route API」の使い方
このAPIを使えばgatsby-node.jsの複雑なコードを大幅削減してシンプルにすることが出来る。合わせて「タグ(カテゴリ)別ページ」を作る方法も記す。



これまでのgatsby-node.js
マークダウンファイルごとにページを生成する場合はgatsby-node.jsにてcreatePagesというコードを使っていた。
その中でidとslugをgraphQLから抽出してtemplateのblog-post用ページに投げていたはず。
更にそのblog-postページ内でgraphQLを発行して内容を取得していると思う。
とにかくこれが複雑な手順となっており混乱を招いていた。
今回のAPIを使うことでこれをシンプルにまとめることが出来る。
公式の解説
2020/11にリリースされた新しい機能。
このAPIに関しては公式の解説を読んでいただきたいところではあるが、英語なのでこちらで噛み砕いていきたい。
Announcing Gatsby’s new File System Route API | Gatsby
公式によるとまず
exports.createPages = async ({ graphql, actions, reporter }) => {
//以下省略となっている関数(createPages)をまるごと削除する。
※createPagesの関数。この中でcreatePageを読んでいるので間違えないように。
これを消すだけでかなりコードが削減されるはずだ。
ただし、これだけではページが作られなくなるので当然BLOG記事は見れなくなる。
pages配下に特殊なファイルを生成
次にsrc > pages 配下に特殊な名前のファイルを作る。
ここでは公式と同様に{MarkdownRemark.fields__slug}.jsというファイルを作る。
このファイル名自体にgraphQL用のクエリが入っていると考えれば良い。
このファイルにとりあえずテストのため次のコードを入れておく。
import React from "react";
const TestPage = ({ params, data }) => {
return (
<main>
<h1>ok</h1>
<p>ID:{JSON.stringify(params)}</p>
<pre>DATA:{JSON.stringify(data, null, 2)}</pre>
</main>
)
};
export default TestPage;最終的にはここでgraphQLを使って記事を取ってくるのだが、とりあえずはテスト。
この状態でdevサーバーを建ててblog記事のslug(どの記事でも良い)にアクセスしてみよう。
※エラーが出る場合はgatsby cleanをしてからdevすると良い。
今回は次のようなサンプルと同じmdが入っているので
http://localhost:8000/hello-world
という記事に試しにアクセスしてみる。
結果は
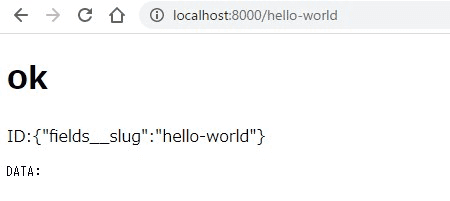
paramsにデータがはいっており、dataには何も入っていないことが分かる。
graphQLのクエリを発行していないので当然ではあるが、この状態ではURLにはアクセスできても記事の内容は表示されない。
とはいえマークダウンファイルごとにページは作られているのは理解できるはずだ。
graphQLのクエリを付ける
上で変な名前のファイル名をつけたのを思い出してほしい。
このファイル名自体がFile System Route APIの書式。つまりgraphQLのクエリとなり次の動作をする。
- とってきたslugがURLとなる(ファイル名で指定)
- さらにこのファイル内部の
graphQLクエリにidを渡す(いかなるファイル名でもidが渡る)
この仕組を利用して記事データを取得する。
次のコードを下部に追加。
export const pageQuery = graphql`
query TestQuery($id: String!) {
markdownRemark(id: { eq: $id }) {
id
frontmatter {
title
}
}
}
`単純にidとtitleを取ってくるだけだが、引数に$idが入っている。
idはいかなるファイル名でも自動的に渡ってくるのでAPIの仕様として覚える。
※ご存知かと思うがこのクエリで得られる結果はdataに入る
結果
さて、上のクエリをいれて実行すると
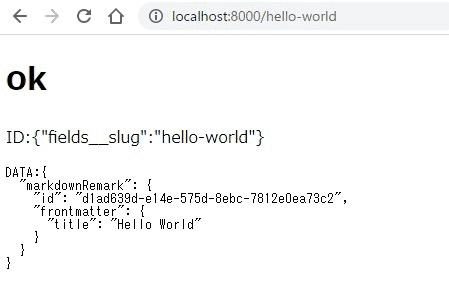
BLOGの1記事分のデータが正しく取れている。
これでgatsby-node.jsからcreatePage関数を抜き取ってスマートな状態にすることができるはずだ。
ファイル名の表記法
ちょっと特殊なので簡単な表記法。より詳しい使い方は公式を参照。
まずルートの階層の名前のあとドット「.」を打って次の階層。
更に下の階層へ行く場合はアンダースコアを2つ「__」入れて指定するらしい。
というわけで{MarkdownRemark.fields__slug}.jsとは次のクエリを取ってきてそれをURLとできるので
そのままslugがURLになる。
応用編:id以外を取りたい
さて、ココからが本題。
このid以外をとってくる方法が全くわからず試行錯誤した結果なんとか成功したので記す。
タグやカテゴリページを作る
タグ(カテゴリ)ページを作りたい。
まず記事のyamlにタグ(カテゴリ)を追加する必要がある。
---
title: Hello World
date: "2015-05-01T22:12:03.284Z"
description: "Hello World"
tag: "tag1" #ここを追加!!
---他の記事にtag2というデータも追加した。
タグページのファイル名
今回はタグ名でページをまとめたいので次のファイル名にする。
{MarkdownRemark.frontmatter__tag}.js
これでタグごとにURLが発行されるはずである。
もちろんmdファイル越しにタグが重複していてもOK。
コード
次のコードをで保存する。
import React from "react";
import { graphql } from "gatsby";
const TagPage = ({ params, data }) => {
console.log(data)
return (
<main>
<h1>ok</h1>
<p>ID:{JSON.stringify(params)}</p>
<pre>DATA:{JSON.stringify(data, null, 2)}</pre>
</main>
)
};
export const query = graphql`
query test(
$frontmatter__tag: String
) {
allMarkdownRemark(
filter : {
frontmatter: {
tag: {eq: $frontmatter__tag}
}
}
) {
nodes {
id
fields {
slug
}
frontmatter {
tag
}
}
}
}
`
export default TagPage;クエリは「特定のタグで絞った記事一覧を出す」という動作を行っている。
実行結果
./tag2/にアクセスすると
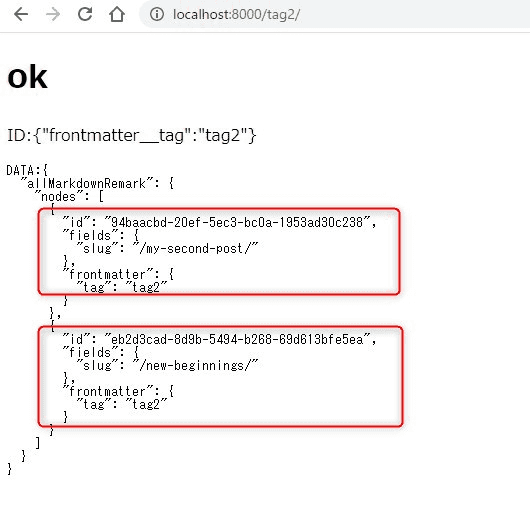
予め設定しておいたタグにtag2と入っている記事一覧が拾えたことになる。
※hello-worldのタグは"tag1"なのでここでは表示されないのが正しい。
ここが重要!
このAPIで$id以外の引数を設定する場合に特に注意が必要で次のようにする必要があった。
$frontmatter__tag: Stringここを**$tagとすると正しくデータが取得できず**悩んでいたが上のような書式が正解の模様。
tagの前に階層構造を指定する必要があるらしい(ルート階層は不要)
今の所ドキュメントにこれが乗っておらず試行錯誤した結果偶然発見した。
※どこかに乗っている場合は申し訳ない
さいごに
このような方法がわかればあとは色々な応用が利くのではないだろうか。
ただ、少し複雑で私の検証結果だけで記事を書いているので間違っていたら申し訳ない。
もしあればそのその都度修正する予定である。


