

【Gatsby.js】createResolversを使おう【GraphQL】
createResolversを使うとGraphQLにデータを登録し終わった後にもう一度読み出して処理したり項目を増やしたりできる。GraphQL側の機能なのでGatsby.jsで使うには少々コツが必要。



| 使用ソフトウェア | バージョン | 備考 |
|---|---|---|
| Gatsby.js | 4.14.1 |
予め注意
この記事はGatsby.jsのみならずGraphQLの概念もそれなりに理解していないと理解も難しく、解説も難しい。
私にできる範囲でわかりやすく書いているつもりだが、かなり上級者向け内容となっており概念的な間違い等があるかもしれない。
あくまで参考として読んでもらえたらと思う。
createResolversとは
Gatsby.jsではgatsby-node.jsにおいてマークダウンなどのデータからページを作成する仕組みだ。
このときonCreateNodeにてcreateNodeFieldという関数を使うと各Nodeに項目を自由に追加することができるということは中級者ぐらいでも知っているはずだ。
しかし、このときに「他の記事を読み込んで、その内容から一部抽出して項目を追加」のような複雑なことはできない。
createResolversを使うと一度全ての記事データをGraphQLに追加した後に、各データに対して再度クエリを発行して項目を処理/追加することができる。
どんなときに使うのか
例えばBLOGの各記事において「関連記事」を表示する場合どうしたらいいだろうか。
上でも書いた通りこの実装には各記事を処理しながらも他の記事データと照らし合わせて関連記事を生成しないと再現できないはずだ。
ここでcreateResolversの出番というわけだ。
他にも、私のサイトに実装されている「シリーズ記事」の実装において、同じシリーズで登録されている別の記事を自動で取得するためにcreateResolversが使われている。
もう一つ例をあげると、公式のサンプルでは「著者」の名字と名前の2項目をユーザー側で入力しておき、リゾルバを使ってフルネームという項目を後から生成する例がある。
createPagesでも実装できない?
実は関連記事のような例で言えばcreatePagesを通して無理やり作れそうだ。
createPagesではallMarkdownRemarkのクエリにより全記事を一旦取得してからページ生成に入る。
そしてcreatePage関数のcontextという値にデータを登録してやることで、各ページに追加でデータを流し込むことができる。
ということは、多重ループで別の記事の情報を取ってきてcontext経由で別データを流し込むことが実は可能かもしれない(書いておいて自分はやったことない)
それはそれで良いと思うのだが、いくつかデメリットがあるので次に書いていく。
File System Route APIだとそれはできない
File System Route APIという機能がありGatsby-node.jsにコードを書くこと無く記事ページを生成することができる。
この機能を使っている場合上記テクは使えない。
【Gatsby.js】コードを削減する「File System Route API」の使い方 | 謎の技術研究部
GraphQLからデータが取れるのであればFile System Route APIで生成したページでもデータが読み込める。
特殊な集計はできない
またcontextを経由するということは各記事(ページ)に直接データを流し込むということなので、例えば「全記事に登録されている平均タグ数を取得するクエリ」のようなものは作れない。
まぁそんなものは作らないかもしれないが。
コードが煩雑になる
上のように特定の記事を処理中に、更に別記事のデータを取ってきて処理してくっつけるということはコードが煩雑になる。
GraphQLに任せられる箇所は任せてしまったほうがスマートかと思う。
使い方のまえに
まずGraphQLの基本概念について最もわかりやすいと思ったページが次。
外部サイト:これを読めばGraphQL全体がわかる。GraphQLサーバからDB、フロントエンド構築 | アールエフェクト
※この場を借りて素晴らしい記事をありがとうございます。
注意点
上記サイトにてリゾルバの解説もあるため概念理解のためにぜひとも読んで頂きたい。
ただしGatsby.jsは専用の関数を通してリゾルバを作成するため上記とはコードの記述が異なるため注意してもらいたい。
基本
ここからが本題。
まずはgatsby-node.jsにcreateResolversという関数を追加して実装する。
次が最小構成のサンプル。
exports.createResolvers = ({ createResolvers }) => {
const resolvers = {
Query:{
test:{
type: 'String',
resolve: async (source, args, context, info) => {
return "test成功"
}
}
}
}
createResolvers(resolvers)
}これをdevelopモードで起動後GraphiQLで見ると
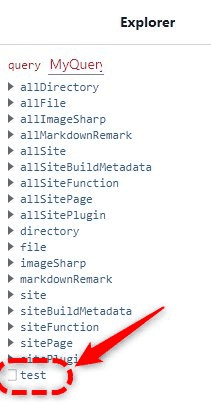
一番上の階層にtestという項目が増えているのがわかる。
ということは、次のクエリでこのtestが取得できる。
query MyQuery {
test
}結果は
{
"data": {
"test": "test成功"
},
"extensions": {}
}これは実にシンプルでtestという新しいクエリを作った形だ。
すでに情報量が多すぎて意味不
「testの取得が簡単なのはわかる。だがそれを生成するリゾルバが意味不すぎる」と思ったあなた。
全くもって同感である。
順番に解説してみる。
Query : {}
まず意味不なのはQuery : {}から始まっているということ。
なんでココから始まっているのかというと「新しいクエリを追加しますよ」ということだからだ。
例えばここをMarkdownRemark:{}で始めると既存のMarkdownRemarkのデータ項目をいじりますよという意味になる。
testというクエリは全く新しいものなのでQuery:{}で書き始める。
さすがにconst resolvers =やcreateResolvers(resolvers)あたりは空気で意味を理解できると思うので解説しない。
type
このtest:{}自体が新しいクエリの宣言ということはわかると思う。
ではその中のtypeが型を表していることもわかると思う。
重要なのはこのtypeを書かないと正しく動作しないという点。絶対に省略してはならない。
ここの型指定がおかしくてもエラーで動作しない。
同じgatsby-node.jsのcreateSchemaCustomizationにてデフォルトでいくつか定義してあるので参照。
resolve
ぱっと見で明らかに難しそうなのは次の解釈。
resolve: async (source, args, context, info) => {
return "test成功"
}ひとまずreturnがあるので、ここにスクリプトを書いてreturnで帰った値がクエリの結果になることはわかると思う。
つまりはsource, args, context, infoに入ってくるデータを元に新しいデータ項目を作って返すことになる。
じゃぁこれをどう使うのかということが一番難しいのだけれど、この例だとこれらは使わないので別の例で解説していく。
MarkdownRemarkをいじってみよう
ここまでの例ではtestという全く新しいクエリを作ったが、今度はMarkdownRemarkという既存のクエリに項目を追加してみようと思う。
サンプルコードは次
const resolvers = {
MarkdownRemark: {
test: {
type: 'String',
resolve: async (source, args, context, info) => {
return `test ok`
}
}
}
}さて、これはこれまでで解説しているのでわかると思う。
MarkdownRemarkにtestという項目を追加しているので
query MyQuery {
markdownRemark {
test
}
}上のようなクエリがエラー無く動くようになる。
当然だが全ての記事に"test": "test ok"というデータが入るだけだ。
このtestのクエリはallMarkdownRemarkのnodesの中にも追加されるのでそちらで確認すると全てのデータに追加されていることがわかる。
markdownRemarkでテストすると1件しか出てこないので混乱しないように。
source
ここでようやくresolveにはいってくる引数sourceを試す時が来る。
上のコードのリターンの部分だけ次へ変更
const resolvers = {
MarkdownRemark: {
test: {
type: 'String',
resolve: async (source, args, context, info) => {
return source.frontmatter.title //ここを変更!!!!
}
}
}
}この状態で今回はallMarkdownRemarkからデータを取ってみる。
query MyQuery {
allMarkdownRemark {
nodes {
test
}
}
}結果は

本来frontmatter.titleに入っているデータがfrontmatterと同じ階層に作ったtestにもコピーされた。
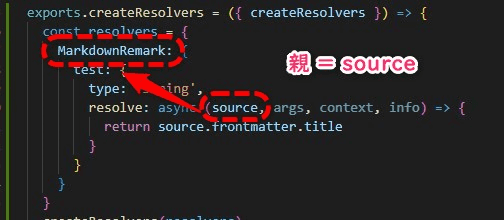
つまりここでのsourceは、上の階層(つまり親)で指定しているMarkdownRemarkのことを差している。
混乱に注意
sourceの後いきなりfrontmatterがきているので混乱しがち。
いきなりfrontmatterから書き始めて良いのはMarkdownRemarkの中のリゾルバであるため。
context
次は引数のcontextを使う。
これに関しては調べた限りcontext.nodeModelというメソッドとセットで使う以外の方法が調べても出てこないのでセットで覚えてしまえばよさそうだ。
公式参考:Node Model | Gatsby
何をするもの?
ここではじめてリゾルバの中にクエリを差し込むことによって更に複雑な処理を可能にする。
要するに最初に言った通り「とある記事から更に別の記事を参照する」といったことを可能にする。
findAll(findOne)
context.nodeModelからメソッドで複数の処理が用意されている。
findOne: クエリを通して1個だけデータを取ってくるfindAll: クエリを通して複数個データを取ってくる
違いはこれだけなのでここは詳しくやる必要はないだろう。
context.nodeModel.findAllで例を出してみる
const resolvers = {
MarkdownRemark: {
test: {
type: 'MarkdownRemark',
resolve: async (source, args, context, info) => {
const result = await context.nodeModel.findAll({
type: 'MarkdownRemark',
query:{
filter: { frontmatter: { title: { eq: "Hello World" } } }
}
})
return result
}
}
}
}findAllのメソッドにオブジェクトを渡す。
1つ目はtype。
2つ目にクエリを入れる...のだが、ここの実例をwebで調べるとfilterを使ったものが殆ど。
通常のクエリだとどうやってもエラーがでるので「もうこういうもんだ」とおぼえてしまっても良さそうに思う。
ここは力及ばずで申し訳ない。
このクエリは何をしているのか
findAllの中にtype: 'MarkdownRemark'を入れてqueryを削除した場合、全てのマークダウンリマーク≒allMarkdownRemarkが帰る。
このqueryはそれを更にフィルタするときに使えるようだ。
ここではMarkdownremark > frontmatter > title が Hello World になっている記事に絞って全部とってくるというクエリになる。
かなり分かりにくい実行結果
これにより「各記事の中にHello Worldがタイトルとなっている別記事のMarkdownremarkが埋め込まれた」結果が出てくる。
つまり一つのtestをクエリするだけでMarkdownremarkのなかに更にMarkdownremarkが入っているものが取り出せるわけだ。
もう完全にワケワカメだと思うがクエリ結果を出しておく。
次のクエリを発行すると
query MyQuery {
allMarkdownRemark {
edges {
node {
test {
frontmatter {
title
}
}
frontmatter {
title
}
}
}
}次のような結果が帰ってくる。
{
"data": {
"allMarkdownRemark": {
"edges": [
{
"node": {
"test": {
"frontmatter": {
"title": "Hello World"
}
},
"frontmatter": {
"title": "Hello World"
}
}
},
{
"node": {
"test": {
"frontmatter": {
"title": "Hello World"
}
},
"frontmatter": {
"title": "My Second Post!"
}
}
},
{
"node": {
"test": {
"frontmatter": {
"title": "Hello World"
}
},
"frontmatter": {
"title": "New Beginnings"
}
}
}
]
}
},
"extensions": {}
}本来の記事の内容とは別の内容が差し込まれている。
リテラブルなオブジェクト
上のリゾルバの例でresultの変数にはリテラブルなオブジェクトが入っているので.mapなどでループして処理することが可能なので覚えておくと良い。
公式の例ではconst { entries } = await context.nodeModel.findAll({となっておりentriesという名前で受ける。
一応次の例で全ての記事のfrontmatterをconsole.logするテストは成功した
const { entries } = await context.nodeModel.findAll({
type: `MarkdownRemark`
})
entries.forEach((a) => {
console.log(a.frontmatter)
})contextのメソッドは他にもある
context.nodeModelのメソッドはfindAllやfindOne以外にもある。
先程あげたページに記載されているので気になる場合は参照。
公式参考:Node Model | Gatsby
もはや調査して解説する気力は残っていない。
シリーズ記事の一覧を引いてくる例
最後に本HPで実際に稼働しているシリーズ記事を引いてくる例を掲載しておく。
const resolvers = {
MarkdownRemark: {
seriesPosts: {
type: ['MarkdownRemark'],
resolve: (source, args, context, info) => {
return context.nodeModel.runQuery({
query: {
filter: {
frontmatter: {
tags: {
in: [source.frontmatter.seriesTag],
nin: [null]
},
},
},
},
type: 'MarkdownRemark',
})
},
},
},
}この例だと上で使ったsourceと組み合わせる事によってマークダウンのfrontmatterに書かれたタグを読み取って該当する記事をひっぱってくる仕組み。
runQueryはv4以降deprecatedなので非推奨によりfindAllへの書き換えを行った。
findAllにメソッドを書き換えただけだとエラーが出る。
上の解説でも書いたことを踏まえて、次のコードで修正した
//asyncを追加
resolve: async (source, args, context, info) => {
//runQueryをfindAllへ変更しentriesで受ける
const { entries } = await context.nodeModel.findAll({
//省略
)}
}
//entriesを返す
return entries以上
正直な所、過去最高に解説が難しいと判断したためほぼ書きなぐっている。
書こうと思えば何ページものボリュームでかけそうだが、こんなマニアックなコードを見ている人も殆ど居ないだろう。
この部分を読んでくれている人がいれば奇跡だとさえ言える。
またこのレベルのコードの公式Docを読み始めるとgatsby.jsにはもっともっと難しいことがたくさん眠っていることがよく分かる。
そうするとリゾルバはその深淵の入り口にすぎないとも言える... がひとまずこれが使えると今後かならず役に立つケースが出てくるとは思う。
かなり乱雑な記事になってしまったが、一人でも誰かの役に立てば幸いだ。


