

ControlNet(v1.1)の詳しい解説!輪郭やポーズから思い通りの絵を書かせる【Stable Diffusion】
AIイラストはPromptだけだと思い通りのポーズが出せない。そこで既存の線画やポーズから出力をコントロールする手法がControlNet。できるだけ細かいところまで設定を見ていく。



ControlNetがv1.1にアップデートされたため随時記事更新中!推定モデルの解説はほぼ網羅(一部あまり使われてないと思われるものは掲載していない)
かなり頻繁に更新しているため、履歴を最下部に掲載
最終更新時のControlNetのバージョン:1.1.201
はじめに
この記事はStable DiffusionのExtensionであるControlNetのより深い解説を目指す。
なにをするもの?
今まで殆ど運任せだった画像生成だが、ControlNetを使うことである程度ユーザーがコントロールすることができるようになるというすごいもの。
基本的には入力画像から線画やポーズを推定して別の画像を生成する。
わかりにくいのでいくつか例を掲載する。
ポーズだけ抽出して全く別の画像に
次の画像からポーズだけ抽出して新しい画像を生成できる(openpose)

このポーズのマーメイドにしてみる

完璧ではないが、このようにポーズだけ抽出して新しい絵に適用することが出来る。
塗りを変える
例えば先日自作したウマ娘の洋服を着せたCGモデルの画像をAIに通す場合

上は元絵
ControlNetを使用し線を維持したまま、塗りを変えたのが次の例(cannyを使用)
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|

|

|

|

|

|
どれも同じ輪郭線を保ちながら色や顔が違っている。
これはi2iだけではできなかった。
i2iだけでやるろうとすると元絵とほとんど同じ画像が出てしまう。
指を正確にするツールとして(上級者)
ControlNetが線を正確に再現する作用を利用してAIが苦手な指を正確にする方法もある。

この例は自前で3DCGモデルと指の推定用画像を用意する必要があるので上級者向けだが後ろの項目にて簡易解説を付けている。
次の画像は指がきれいに描画できているが、3DCGの元絵をSoft Edge推定しているだけだ。

その他にも様々な機能があるため、少々長い記事となるが解説していく。
ControlNetのGitHub
このアルゴリズムを考えた大元は次のモデル(v1.1)
GitHub - lllyasviel/ControlNet-v1-1-nightly: Nightly release of ControlNet 1.1
そしてこれを使いやすくautomatic1111氏のweb UIに対応させたのが今回利用させていただいたもの。
GitHub - Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
この場を借りて公開に感謝いたします。
インストール等
恐らくここ以降の記事を読むユーザーはStable Diffusionのweb UIには詳しい人が多いだろうという想定なので冗長になりそうな箇所は省略する。
エクステンションを入れる
Web-UIのExtensionで導入する。
リポジトリのURLを貼り付けるだけでインストールできる。
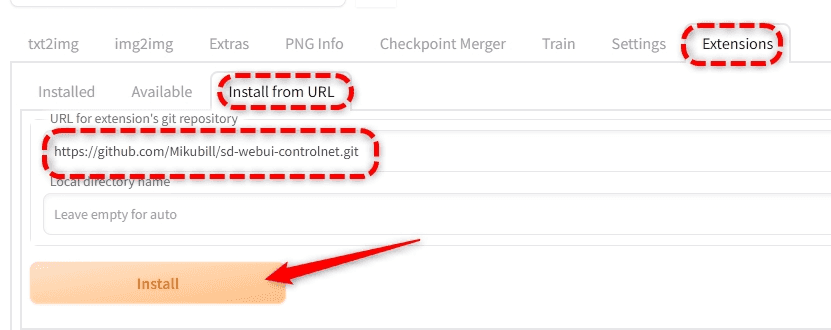
URL: https://github.com/Mikubill/sd-webui-controlnet.git
2023/03/04時点ではExtensionのリストから検索してもインストールが出来る模様。
Google Colabに入れる場合
Web-UIからインストールするとエラーになる場合がある。
その場合は次のようにextensionsフォルダ下でgit cloneしてやれば完了。
opencv-pythonも別途必要らしく念のため入れている。
%cd stable-diffusion-webui/extensions/
!pip install opencv-python
!git clone https://github.com/Mikubill/sd-webui-controlnet.git輪郭やポーズを推定するモデルが必要
ControlNetはインストールしただけでは動作しない。
「輪郭を取りたい」「ポーズを取りたい」「奥行きを取りたい」などの目的に合わせて別々のpthファイルをDLしておく必要がある。
このアルゴリズムの種類とpthファイルについて、詳しくは後の項で解説する。
次のサイトに抽出する手法別にデータが分かれている。DL用のURLは次。
v1.1対応版:lllyasviel/ControlNet-v1-1 at main
推定用モデル(pth)の保存先
重要:使いたいアルゴリズムに対応したものだけをDLすればよいので先に記事を一読してからのDLを推奨
便宜上先に保存フォルダだけ掲載しておく。
extensionのmodelフォルダにpthファイルを保存。
合わせて同名のyamlファイルもDLして保存しておく。
ここはStable Diffusion本体のmodelフォルダではないので注意。
具体的に次のようなフォルダになるはず。
stable-diffusion-webui/extensions/sd-webui-controlnet/models/~~~~.pthまた、これ以外にも推定用のモデルがあれば使える模様。
v1.0までのモデルは次のサイトからDLする。1.1以降でも古いモデルを使用可能。
どういう原理?
そもそもどういう仕組でControlNetが作用するのか。
イメージとしては次のような手順。
- 元となる画像を
ControlNetに入れる - その画像から推定画像(アルゴリズムで変わる)を生成
- その推定された画像を元に新しい画像を作る
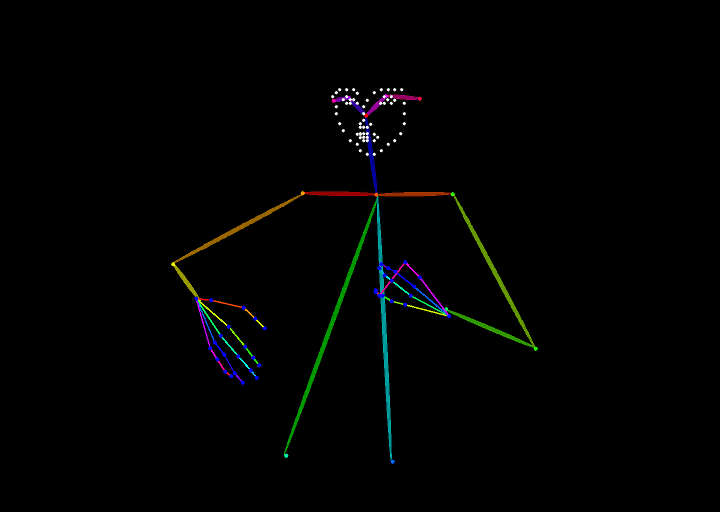
実際に試すと次のような画像になる。
| 元画像 | 推定された画像(openpose) | 出力された画像 |
|---|---|---|

|
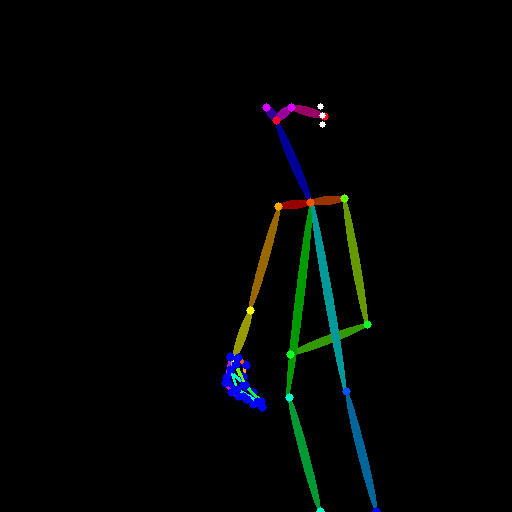
|

|
この推定用に生成される画像は、ユーザーが選択するアルゴリズムによってさまざま。
次の項ではどのようなアルゴリズムでこの推定画像(マップ)が出るかをまとめておく。
できること一覧
上で説明した推定するモデルについて、それぞれがどういうものか、何ができるのかを具体的に一覧にしておく。
また、各モデルのpthファイル名も掲載しておく。欲しい機能だけDLしてインストールすれば良い。
Soft Edge (旧:hed)
ファイル名(v1.1):control_v11p_sd15_softedge.pth
入力されたイラストの線と認識される部分を非常に高精度で抽出する。
グレースケール全範囲を利用することによって線の強弱まで取っていると思われる。
| 推定画像 | 出力画像 |
|---|---|

|

|
Denoising=0.75にも関わらずディティールを維持したかなり美しい画像となった。
冒頭のギターを弾いている画像もSoft Edgeで生成している。
| 入力画像 | 出力画像 |
|---|---|

|
|
このようにCGをリペイントする場合かなり強力。私が最も利用しているアルゴリズム。
LineartやCannyよりも線を確実に捉えるのが特徴。
元絵を忠実に再現したいときはかなり強力。
Soft Edgeは4種類ある
Soft EdgeはPreprocessorを選択するときに次の4種類から選ぶ。
- softedge_hed
- softedge_hedsafe
- softedge_pidinet
- softedge_pidisafe
迷うかもしれないがあまり難しく考える必要はない。
まずhedsafeは従来のhedよりも推定画像の細かい部分で画像が壊れるケースを修正したもののようだ。
ならhedsafeのほうがいいのではないか?というとそういうわけではなく、その分画像を生成する際の品質を犠牲にする。
pidinetはhedと殆ど同じ用途だが内部アルゴリズムが違うため、亜種だと思えば良い。
具体的にpidinetに変えるとどういう変化があるのか、というところまでは指摘できないので試して見る他無い。
Soft Edgeを試す順番
公式では次の優先順位を推奨している。
クオリティを求めるなら:SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
推定画像を壊れにくくするなら:SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
v1.1にてhedからSoft Edgeに名称変更。
v1.0を使う場合control_sd15_hed.pthを利用する。
公式によるとv1.1のモデルを使ったほうが精度が上がるとのこと。
Lineart
Soft Edgeに似ており、元絵から線を抽出する。
DLするpthファイルは次の2つので分かれる。
control_v11p_sd15_lineart.pthcontrol_v11p_sd15s2_lineart_anime.pth
こちらは人間が書く「線画」のような推定画像になるのが特徴。
抽出された線自体を別ソフトで使うときなどで非常に強力。
| 元画像 | 抽出された線画 |
|---|---|

|

|
一例として次のようなことが出来る
| 色トレスとして(別ソフトで合成) | 線画から塗り直し(着彩)に利用 |
|---|---|

|

|
他との違いは「薄い線を無視して抽出する」という点。
つまりSoft Edgeのような正確に元絵を再現したい場合というよりも塗り直しや一部書き直しながら再生性といったケースで有用。
こちらはかなり種類があるため詳しい解説を別ページに掲載してるので次を参照してもらえたらと思う。
ControlNet(v1.1)のLineartを極める!他機能との違いも!【Stable Diffusion】 | 謎の技術研究部
openpose
ファイル名(v1.1):control_v11p_sd15_openpose.pth
openposeはAIによるモーションキャプチャなどで使われているもの。
人物の四肢の位置や表情を推定しCGのボーンのような棒人間のデータを出力する。
つまり、これまで完全ランダムだったキャラクターが任意のポーズで生成できるようになった。
おそらく最も使われている重要な機能。
複数の種類がある
openposeにはたくさんの種類があるので簡単にまとめる。
- openpose:ボディのみ(表情や指は推定はしない)
- opsenpose_face:表情とボディ
- openpose_faceonly:表情のみ
- openpose_full:表情+ボディ+指(つまり、全部)
- openpose_hand:ボディと指
※うまい言い回しがないので「顔・体・手足」の位置をまとめて「ボディ」としている
混乱する必要はなく対応するものを選べば良い。
処理速度が大きく伸びるわけでもないので特に理由がなければfullで良いのではないだろうか。
openpose_fullのサンプル
| 元画像 | 推定画像 | 出力画像 |
|---|---|---|
|
|
|

|
この結果から分かることはポーズについてはほぼ完璧。あらゆる構図を意識的に作り出すことができそうだ。
ただし指は相変わらず崩れているので、こちらの対応は他の工夫が必要そうだ。
openpose_faceonlyのサンプル
顔の情報を取る場合2023/04/21時点では表情がかなり大きな元画像か、正面を向いている画像のみだった。
faceonlyが成功したのは次のような画像
| 元画像 | 推定画像 | 出力画像 |
|---|---|---|

|
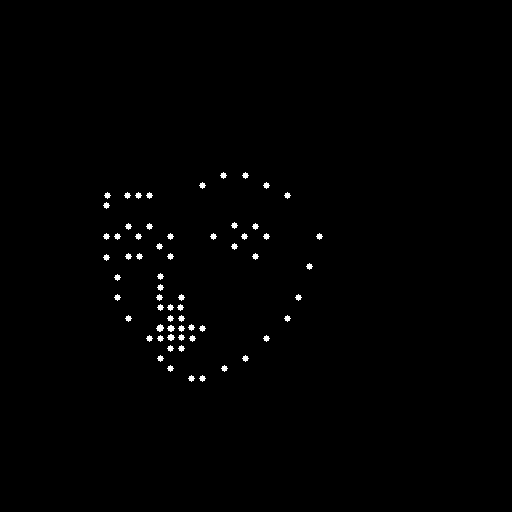
|

|
現時点ではできるだけ角度がついていない表情の画像を用意するのが重要そうだ。
v1.0のファイル名:control_sd15_openpose.pth
v1.1で表情の追加など大きく性能アップ。古いバージョンをあえて使う理由はないだろう。
mediapipe_face
このモデルはlllyasviel氏のControlNetとは違うものなので別のサイトからモデルをDLする。
CrucibleAI/ControlNetMediaPipeFace at main
上のサイトからcontrol_v2p_sd15_mediapipe_face.safetensors
こちらも表情を抽出するモデル。
アニメ顔でもバストアップぐらいまではかなりの精度で認識していたので使いやすいかもしれない。
| 元画像 | 推定画像 | 推定画像から生成 |
|---|---|---|

|

|

|
口を開けた絵を出すことができた。
次は少し角度がついた表情+ちょっとカメラを遠めに。
| 元画像 | 推定画像 | 推定画像から生成 |
|---|---|---|

|

|

|
こんな角度でもうまく抽出できているので、表情を取るだけならこちらはかなり優秀かと思う。
ただし、抽出時に認識が甘く輪郭線が大きく出てしまった時に不自然なぐらい大きな顔が出てしまうというケースがあった。
元絵から抽出する段階で失敗しないように心がけたい。
推定画像を歪ませたらどうなる?
画像を曲げてしまったらどうなるか、というテスト。
推定画像を変形してみた。
| 推定画像 | Weight=1 |
Weicht=2 |
|---|---|---|

|

|

|
何度か試したがweight=1の場合は概ねきれいな顔に補正される。
weight=2にすると生成途中はひねった顔が出てくるのだが、徐々に美しい顔に戻る。たまに顔でないものが描画されたりする。
変顔を作ることは出来なかったが、ちょっと不自然な表情にみえるので、あえてそこを狙って使う可能性はあるかもしれない。
shuffle
ファイル名(v1.1):control_v11e_sd15_shuffle.pth
執筆時点でv11eとなっているのでExperimental(実験的)機能
公開初期の時点ではSeed固定が無効との報告があったが、私が試した時点ではSeed固定が可能になっていた(2023/04/29)
与えられた画像をぐにゃぐにゃに曲げてからもう一度AIにかけるアルゴリズム。
| 元画像 | 推定画像 | 生成された画像 |
|---|---|---|

|

|

|
上のように元画像がPreprocessorでぐにゃぐにゃになってから再度画像を構築するような動きをするので、元画像のイメージを保ったまま別の画像を生成するのに役立ちそうだ。
上の画像では花が描かれているが、プロンプトを空っぽにしても花の画像が生成された。
結構具体的なイメージも継承できる?
次はプロンプトを全く違うものに変えてみる実験
| 元画像 | 生成された画像 |
|---|---|

|

|
| tremendous number of chick toys | cake, pudding |
なんとひよこのおもちゃが幼稚園のパーティーに変化した。
想定していない変化ではあるが、沢山のキャラクタを描画させたい時に使えるTipsとして覚えておくと良いかもしれない。
Depth
ファイル名(v1.1):control_v11f1p_sd15_depth.pth
画像の「奥行き」を推定するモデル。
これは3DCGで利用されるDepth Mapと概念的には同じ画像が利用されていると思われる(黒いほうが奥、白が手前)
奥行きに意味のある画像を生成する場合に使用する他「洋服のシワなどの細かい線は無視するがシルエットは残したい」といった場合にも有用そうだ。
これはcannyやsoftedgeで行ってしまうとシルエット内の線も維持されるので明確に違いが出る。
| 推定画像 | 出力画像 |
|---|---|

|

|
輪郭がはっきりと維持されている。
Depthには3種類ある。
DepthのPreprocessorは次の3種類が用意されている。
- depth_leres
- depth_midas
- depth_zoe
現在のところこれらを切り替えることによって具体的にどう違うのかという解説はされていない。
leresのみ調整できる項目が増えるのでより細かい設定向き?
とりあえずはmidasかzoeを使ってみて、一歩こだわりたいならleresがよさそうだ。

簡単に試した結果。leresはパラメタで濃淡が変化するのでデフォルトで違いが出ている。
私が試した限りではleresのパラメタ調整が甘いと画像が壊れがちなのでこれは上級者向けかも。
3DCGソフトに持っていく可能性
AIで作った画像をCGのテクスチャ等に利用する場合、出力されるDepth mapを直接CGソフトに持っていく利用方法も考えられる。
v1.0のファイル名:control_sd15_depth
v1.1でいくつかのアップデートが施されているようなので新しい方を使ったほうが良さそう。
mlsd
ファイル名(v1.1):control_v11p_sd15_mlsd.pth
こちらは建物や家具といった「直線」を抽出するモデル。
従ってキャラクターには全く無意味となるので注意。
実際に試してみた画像が次。
| Blenderで用意した元画像 | 推定画像 | 出力結果 |
|---|---|---|

|
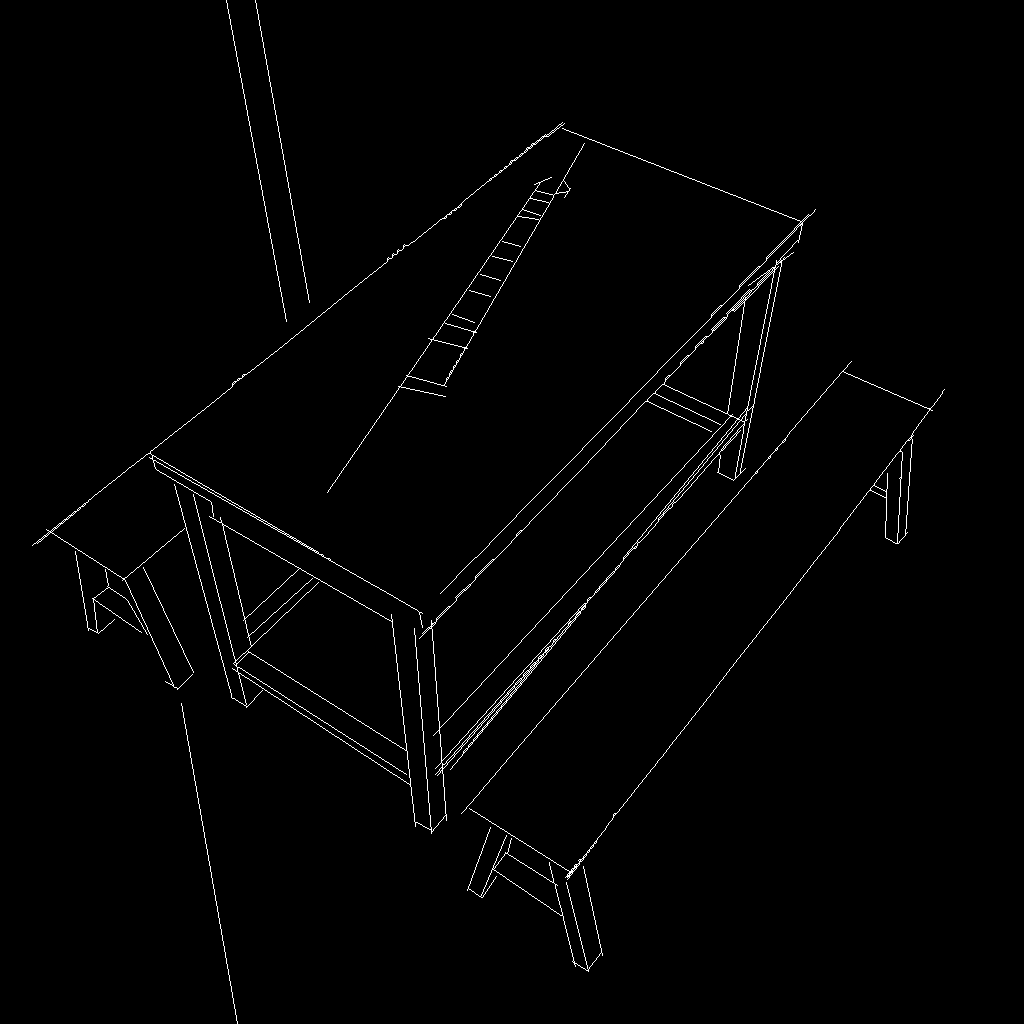
|

|
分かる通りギターのような丸みを帯びたものは無視されている。
しかしながら椅子とベンチは元絵のシンプルさに関係なく非常に細かく書きこまれている。
Soft EdgeやLineartで良いのでは?
単純に線をなぞるだけならSoft EdgeやLineartで事足りるので、この機能は本当に必要なのか疑問があった。
しかし、改めて私が実験した範囲ではmlsdを使うと線以外の箇所の書き込みが増える効果があった。
上のケースではテーブルの他に風景が大きく書き足されているのが分かると思う。
もう一つ比較画像を用意した。
| Blenderで用意した元画像 | Soft Edge | mlsd |
|---|---|---|

|

|

|
Soft Edgeは線に忠実な反面、書き込みがない部分も可能な限り再現してしまっているのではないだろうか。
mlsdに任せるとかなり自由な書き込みが行われており、美しい。
3DCGアーティストなら簡単にこういったものが用意できるので、背景作りは非常に強力かもしれない。
無駄な映り込みを削除して使える?
最初の例でギターが見事に無視されていることが分かる。
これを利用して、写真をAIに通す場合に家具や建物だけ抽出してAI化したい(人などは消去したい)といったケースでも有用なのではないだろうか。
v1.0のファイル名:control_sd15_mlsd.pth
v1.1でいくつかのアップデートが施されているようなので新しい方を使ったほうが良さそう。
機能的には旧バージョンと変わっていない。
Normal
ファイル名(v1.1):control_v11p_sd15_normalbae.pth
ノーマルマップ(法線マップ)を生成し、それを元にするモード。
ノーマルマップは3DCGで使われる概念で、簡易的に解説すると「面が向いている方向」が入っている画像データ。
3DCGではライティングの反射をコントロールしたりするのに使う。
が、AIではライティングというよりDepthのような輪郭線を維持する働きでかなり強力(公式にも同様の解説あり)
つまりDepthやLineartのようにシルエットを維持したまま別の絵に。多少書き直しされてもOKといった時に使うとよいだろう。
Normalのサンプル(v1.1)
| 元画像 | 抽出された推定画像 | 推定画像から再生成(モデルも変更) |
|---|---|---|

|

|

|
normal_baeを使おう
アルゴリズムは次の二種類の方法がある
- normal_bae
- normal_midas
が、公式の解説および私のテスト結果ともにnormal_baeを使うことを推奨する。
normal_midasを使用すると通常のノーマルマップ(CG等で一般的に使われている形式)とは違う種類のものが出力されていると思われる。
こちらが有用なケースは不明。
自作のノーマルマップを使う方法は後の項目に記載。
3DCGソフトに持っていく可能性
AIで作った画像をCGのテクスチャ等に利用する場合、出力されるNormal mapを直接CGソフトに持っていく利用方法も考えられる。
v1.0のファイル名:control_sd15_normal.pth
v1.0は面の方向が物理的に正しくなかったようで、v1.1でアップデートされているとのこと。
normal_midasがどんな方式で、なぜダメなのかは公式の解説も簡易的なため詳しいことは分かっていない。
v1.1で良くなった
2023/05/07:v1.0時点でテストしたときは、精度が低くあまり実用的ではなかったため、こちらは自然と利用しなくなった。
しかし、上の画像にあるように再テストを行ったところStable Diffusion本体のモデルを変更して再生成したにもかかわらず元絵に近いものが出力された。
塗り直しなどにも利用価値があるかもしれないので今後実験したい。
公式サイトでもv1.0よりもかなり強力になっていると明記されているので色々試してみる価値あり。
canny
ファイル名(v1.1):control_v11p_sd15_canny.pth
基本的な目的はLineartやSoft Edge同様に線画に色を付けたい、元のイラストイメージを壊さず別の絵にしたい場合などに使う。
冒頭のサンプルで利用しているのがこれ。
| 元絵 | 抽出画像 |
|---|---|
|
|

|
内部では上のような白線で黒線を挟んだようなラインを抽出し線画として処理している。
2023/05/07:1.0実装当初では話題になったが、現在ではSoft EdgeやLineartのほうが性能が高いと考えられる(個人的意見)ため、こちらはあまりおすすめしない。
v1.0のファイル名:control_sd15_canny.pth
v1.1でトレーニングデータセットの問題がいくつか解消されているとのこと。
scribble
ファイル名(v1.1):control_v11p_sd15_scribble.pth
もともとはその名の通り「ざっくり書いた落書き」をAIでイラストに変換するものだと思われる。
用途としては次の二通りが挙げられる。
- 下手くそな手書き線画(白黒画像)を作り、それをベースに画像を作る
- 元絵の線を抽出し手書き風の線(太い白線)に変換してから画像を作る
他ソフトで白黒画像を用意する場合は「背景が黒、線を白」で用意すること。
cannyやlineartと違うの?
手書きで書いたものはともかく、元画像から線を拾うならcanny, soft edge, lineartと方向性が似ている。
これらとScribbleの大きな違いは「元絵をかなり太い線画に変換してから画像を生成する」という点だ。
かなり曖昧な線を元にすることになるので、元絵の細い線を無視するような動きをする。
| 元絵 | 推定画像 | 出力結果 |
|---|---|---|
|
|

|

|
この例で見ると線が一致しているように見えるが、非常に細かい線が無視され書き直されている。
細い線が消えることで塗りがベタっとなるので、アニメ塗りに変換するような使い方ができた。
しかし、全身のような細かい線が必要な絵はすぐに壊れてしまうので汎用性は低い。研究が必要そうだ。
Scribbleはどういう時に使う?
Windows付属のペイントソフト等で書いたような素人線画をベースにするときは強力。
元絵から抽出する場合Lineart等よりかなり雑に線が拾われるので「線は大きくブレてもいいよ」という時に使うのがベストだろう。
とは言え次で触れるXdogは想像以上に繊細な線を拾うので、私はLineartやSoft Edgeと併用して使用している。
素人線画向けではあるが、AIイラスト上級者向けのモデルだと認識している。
hed, pidinet, xdogの3種類ある
公式に違いは書いてないが、実例で見るとそれなりに差異があるため例を出す。
| scribble_hed | scribble_pidinet | scribble_xdog |
|---|---|---|
|
|

|

|
|
|

|

|
この例の場合hedよりpidinetのほうが線が少なくなり、xdogは荒々しい線で拾われる。
顔のアップはhedがきれいに出ているが、カメラが引いて全身がはいってくると線がぶつかって壊れるのでその場合はxdogに切り替えると良くなる。
線の量に応じて (少) pidinet < hed < xdog (多) と考えて良いかもしれない。
v1.0のファイル名:control_sd15_scribble.pth
以前のモデルでは学習データに無駄なデータが混じっていたようでv1.1で解消されているとのこと。
またユーザーが太い線で落書きを書くことがわかったためそちら側の調整も入っている。
旧fake_scribbleは削除?
segmentation
ファイル名(v1.1):control_v11p_sd15_seg.pth
画像を色でわけると、色分けされた箇所で別々のものが描画できる。
次の例では推定画像を直接用意した(Blenderで色を付けたオブジェクトを置いただけ)
| 推定画像 | 出力結果 |
|---|---|
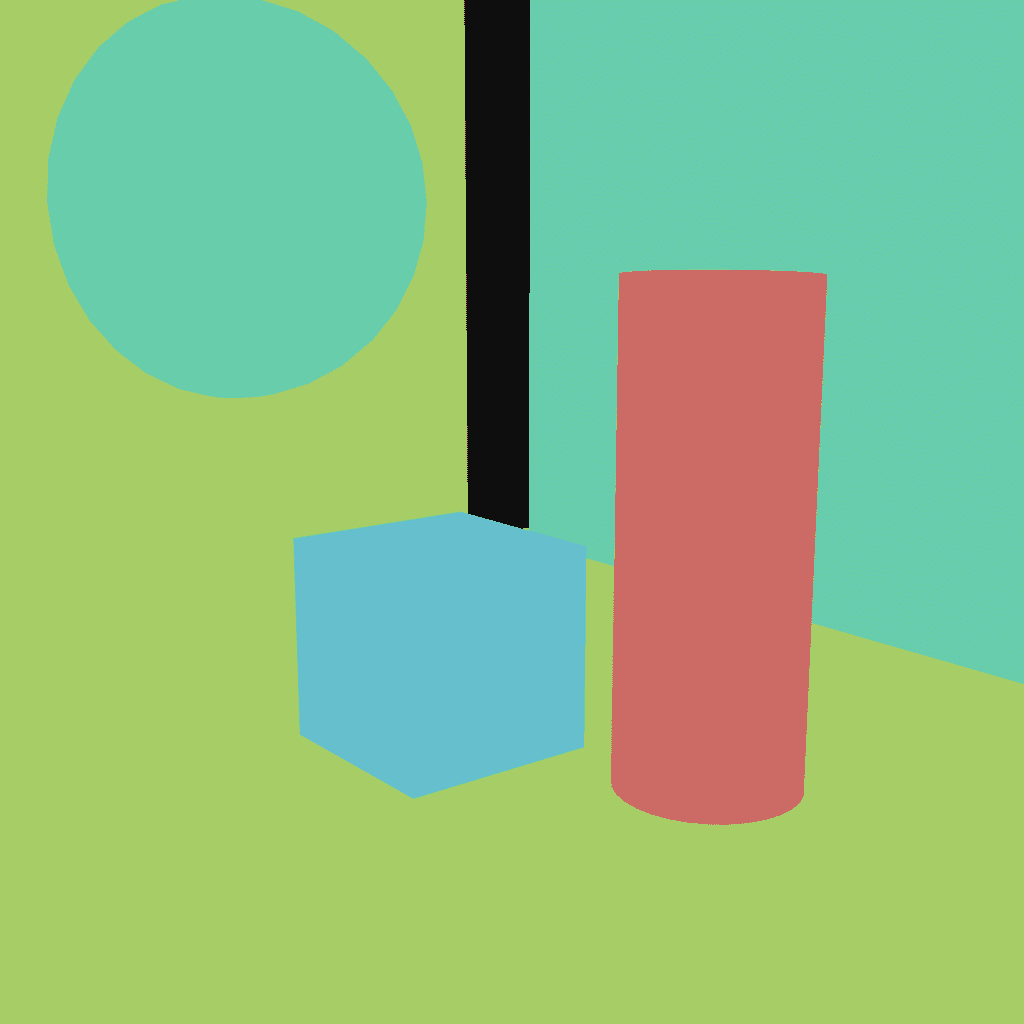
|

|
個人的にはこんな風に簡単な部屋を作るには有用そうに感じている。
あえてキャラクターの部位分けに使っても面白い。完璧ではないが手指も悪くない。
| 推定画像 | 出力結果 |
|---|---|

|

|
ただ、やはり使用目的が明確でない分クセがあり上級者向け。
上の例のように自分で色分けされた画像を用意して使っているユーザーが多いと思われる(Preprocessor=noneで使う)
しかし、あえて元画像を推定させてセグメントに分ける方法もあるためまだまだ可能性が眠っている。
アルゴリズムは気にしなくてよい?
Preprocessorには3種類ある。
- seg_ofade20k
- seg_ofcoco
- seg_ufade20k
アルゴリズムの違いは専門的な内容なので解説が難しいが、出力される推定画像が明らかに変化する。
明確に違いを説明できないため、ここは使用時に何度か切り替えてみることを推奨する。
v1.0のファイル名:control_sd15_seg.pth
v1.1では以前より扱えるカラーが増えているとのこと。
inpaint
ファイル名(v1.1):control_v11p_sd15_inpaint.pth
基本的にはweb-ui本体に付属しているinpaint機能と似ている。
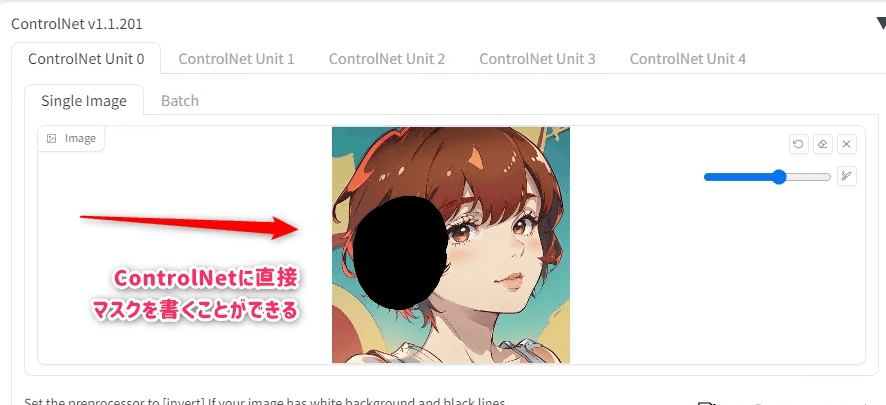
このように直接ControlNetにマスクを書くことができる。
この機能は2種類のPreprocessorがあるので次で解説する。
inpaint_global_harmonious
本体に付属しているinpaintとの違いは次の2つ
- マスクした部分以外もほんの少しAIが手を加える(色味が変わる)
WeightやStartingなどのパラメタが使える
特に1についてが重要でinpaintしたあとの結果がより馴染みやすくなるといった報告が多く上がっている。
つまりinpaintの精度を一段上げてくれる機能だとも言える。
一方でマスクした箇所以外の色味等が若干変化するため完全にオリジナルを維持したいという目的では使えない。
個人的な意見だが本体のinpaintよりもまずはControlNet側のinpaintを使ってみることをおすすめする。
inpaint_only
こちらはシンプルにマスクで塗った部分だけの変化に留め、他は全く変化しない。
恐らく本体付属のinpaintと同等の機能をControlNetで使えるようにしたもの。
塗り直しに使えるかも
inpaint_global_harmonious + マスクを全くかかない状態で使用するという裏技がある。
t2iのControlNetで使用する。
この状態で生成するとpromptやseedを変えても殆ど同じ元絵が出るがpromptに応じて色味が変化する。
これにhires. fixを併用すると、次のような髪の色だけ変更するといったことが可能だった
| 元絵 | 出力後 |
|---|---|

|

|
手順
- 元となる画像生成(t2i)
t2iで作った画像をそのままControlNetへ。プロセッサとモデルをinpaintにする。promptにblue hairを追加Hires. fixをオンにして再生成(マスクを書く必要なし)
この手法だとSeed値をランダムに変更しても髪の色だけ変わったイメージの画像が出てくる。
全体の色味や線画が若干変化する&絵によってはできないこともあるが、結果が様々で面白くなるかも。
試してみてほしい。
tile_resample
ファイル名(v1.1):control_v11f1e_sd15_tile.pth
アップスケールを行う時に全体のイメージを維持しつつ細部を書き込みする補助をしてくれる機能。
| 元画像 | tile resampleを併用したアップスケール |
|---|---|

|

|
非常にシンプルに見えるが、他の機能だけでアップスケールすると線が汚くなったり、無駄な書き込みが増えたりとコントロールが難しかった。
アップスケールを行い絵のクオリティを1段階上げたいというときはまず最初に使うべき機能と言って良い。
3種類のPreprocessor
tile系には次の3種類がある。
迷ったときはtile_resampleを使えば良い。
- tile_resample
- tile_colorfix
- tile_colorfix+sharp
こちらに関する詳しい解説は次のtile_resample専門記事に記載。
【ControlNet(v1.1)】Tile Resampleの解説【Stable Diffusion】 | 謎の技術研究部
reference-only
特殊なPreprocessorでModelが存在しない。
この機能は簡易LoRaと言う人もいるぐらいで、追加学習なしで元絵のキャラや背景情報を引き継ぐような画像が出力される
厳密には違うが「元絵を学習させてから新しい絵を出力させる」といったようなイメージで使うと良いと思う。
referenceは3種類
reference系は次の3種類がある。
- reference_only
- reference_adain
- reference_adain+attn
これらは明確に言葉では説明できないようなので色々試す他無い。
公式からは、最初に試すのがreference_only + Style Fidelity=0.5を推奨している。安定して強力のようだ。
reference_adain+attn + Style Fidelity=1.0が最も最先端の手法だそうなので積極的に面白いものを出そうとする場合は試してみると良い。
似たようなModelありますよね?
実はマスクをしないinpaint_global_harmoniousやPreprocessorをNoneのままにしたshuffleでも同じような動作をする。
それぞれの違いを簡単にまとめると
inpaint_global_harmonious: 元絵を可能な限り再現するような動き。絵は殆ど同じだが色味だけわずかに変えたいといった用途に。suffle: 色味を継承するのでどことなく似通ってはいるが別の画像になる。reference-only: inpaintのように線は再現しないが、似たようなシーンや同じ服装のキャラが出てくる。キャラの特徴を継承して別のシーンを作りたいといった時に。
簡単な例
| 元絵 | i2i |
|---|---|

|

|
| reference-only | shuffle(preprocessor=none) |
|---|---|

|

|
今回はキャラでなく風景を元絵にした。
reference_onlyは風景にキャラクターが新しく増えており「元絵を継承した新しいシーン」になっているのが分かると思う。
まるで「元絵のカメラを引いたらこうなる」といった漫画の続きのような結果。
shuffleを使った例は別の風景になってしまっている。
inpaint_global_harmoniousを使うとほぼ元絵と同じものがでるので掲載していない。
Style Fidelity
この値を上げると元絵の特徴をより強く継承するようだが、強すぎると細かいところで破綻が起きる。
これを調整する場合はBalancedモードで使うこと。
処理が重いので注意
このPreprocessorは恐らくControlNetの中で最も処理時間がかかる。
グラフィックボードの性能との兼ね合いに注意して使用したい。
起動メモ
起動する時にCOMMANDLINE_ARGSに--xformersを指定することが求められている。
ローカルPCのCPUオンリーで動かした場合だけこのオプション無しでも動いた。CPUならいらないかもしれない。
Google Colabを使う場合はこれがなければそもそも起動しないケースを確認。参考まで。
ControlNetパネルの使い方
左下にツールが折りたたまれているのでそこからControlNetのEnableオンにする。
処理したい画像をドラッグ&ドロップしておく。
ControlNetで使いたい機能をControl Typeパネルから選ぶ
PreprocessorとModelを選ぶ(自動的に対応するものだけに絞り込みされている)
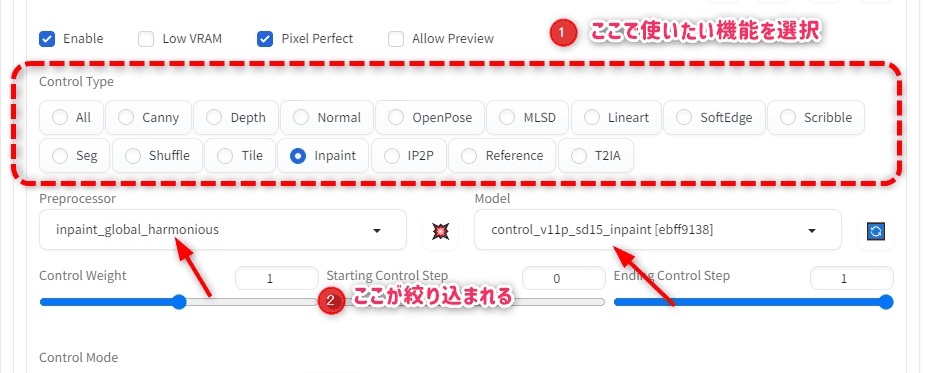
基本的にこれだけ設定してあれば、あとはそのまま生成すればOK。
PreprocessorとModelに上で解説している使いたい機能を指定するが、両方設定するのを忘れずに。
基本はどちらも同じ名称が入っているものを使う。
txt2imgだけでなくimg2imgでも使用可能。
Preprocessorって何?
Preprocessorとは放り込んだ画像から推定画像を抽出してくる処理を行うこと指している。
例えば、ここにdepthを指定するということは「元画像自体は何の処理もされていない生の画像」
であり、これのdepth画像を抽出して、ソレを元にAI絵を書いてね、ということ。
Preprocessorをnoneにする場合は、推定画像を「抽出しない」ということ。つまり自前で(別ソフトで)depthなどの推定画像を自作し、ソレを放り込んでいる場合はnone
なるほど、わからん
まとめると
modelには必ずなにか指定するPreprosessorは自前で推定画像を用意したときのみnone- それ以外は
modelとPreprosessorは対応するものを入れる
ちょっと初心者はここの概念が難しいと思う。
後の項で更に実際に自前のノーマルマップを使用する例も書いているので合わせて読んでもらえれば。
Pixel Perfect

ControlNetはユーザーがメインパネル側で指定したWidth/Heightとは別の画像サイズを指定できるが、これを自動化するもの。
入力されている画像サイズと同じになるよう自動調整されるとのこと。
サイズ調整についてよくわからなければチェックしておけば良い。
Allow Preview

以前までは画像をGenerateしてみないとPreprocessorで生成される推定画像がチェックできなかった。
この機能を利用すると、実際に画像を生成する前に推定画像だけ生成してプレビューすることができる。

Allow PreviewをオンにするPreprocessorにプレビューしたい物を入れる- 真ん中のボタンをクリックで実行
- プレビューが表示される
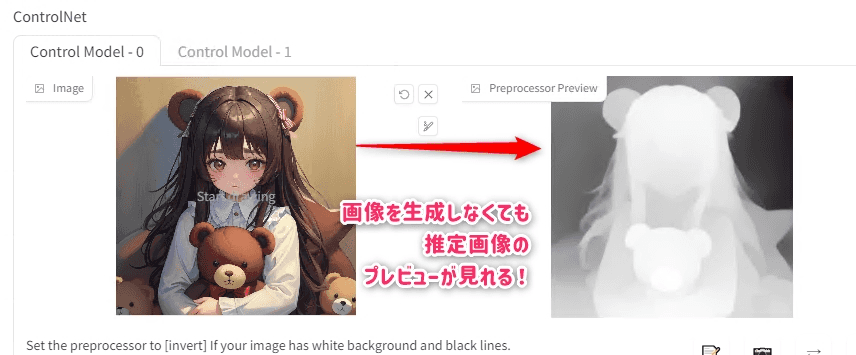
Modelには何も入れなくても正しくプレビューを生成してくれるようだ。
追加のオプション(上級者)
この項で解説するオプションは基本はデフォルトで良い。
さらにこだわった画像を作りたい場合や、画像のエラーに対応する場合に調整すれば良い。
白黒を反転させるだけの「invert」
Preprocessorにinvert (from white bg & black line)というものがある。

これは入力画像の白黒を反転させるだけの機能。
Scribbleのような手書き、または別ソフトから自前で用意する推定画像を使う場合「背景が白、線を黒」で書いてしまうと認識せず意図しない画像が出力されてしまうための措置。
「背景が黒、線を白」で書くのが正しいが、そうでない画像を用意してしまった場合はこちらで反転しよう。
背景が白の場合はInvertが「必要」 |
背景が黒の場合はInvertは「不要」 |
|---|---|

|

|
Blenderから出したDepthを使う時
BlenderのcompositeからDepthを出力したときなど、ワークフローによっては白と黒が逆になるのでこのオプションを利用するという小技がある。
旧Invert Color機能はPreprocessorのこちらに変わった。機能的には同じもの。
しきい値で白黒画像化させる「threshold」
Preprocessorにthresholdというものがある。
これはしきい値をスライダで設定して、それより明るい場所を「白」暗い場所を「黒」で塗りつぶしてしまうもの。
この場合Modelは存在しないのでnoneにする。
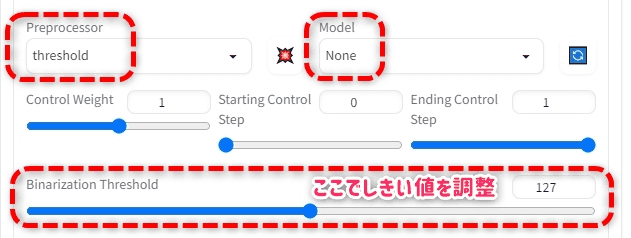
実際の画像を使って生成すると次のようになる。
| 元画像 | threshold=50 | threshold=100 |
|---|---|---|

|

|

|
このようにしきい値を上げていくと、塗りが暗い部分から順番に黒で塗りつぶされていく。
具体的にどういう時に有効なのかはよくわかっていないが、画像処理ソフトでも同じようなことはできるのであくまで補助的な機能かと思う。
ModelにScribbleなどのグレースケールを扱うモデルを入れた場合、この2値化された画像からなにか別の画像が生成されると思うので面白いかもしれない。
Control Mode(旧:Guess Mode)
オリジナルの解説によるとControlNetがプロンプトを自動生成してくれるお手軽モード。
以前の解説によると、ひとまずモデルをテストするときなどに有用とのこと。

設定に3段階あるが、プロンプトの重みを設定する。
Balanced:自分のプロンプトと、自動で付与されるプロンプトを同じぐらいで配合My prompt is more important:自分のプロンプト重視ControlNet is more important:自動生成するプロンプト重視
上は公式に解説がないのであくまで予想。
Guess Modeの実験(v1.0)
v1.0時点での実験。 自前で用意したセグメント画像でテスト
Sampling steps = 50, CFG Scale = 4,Preprocessor = none
| 元画像 | Guess Off | Guess On |
|---|---|---|

|

|

|
| 上と同様でDepth |

|

|
Guessをオンにすることで明らかに線と塗りがハッキリしている。
Guess Modeの実験(v1.1)
ControlNetが新しくなったタイミングでもう一度調査した。
Sampling steps = 50, CFG Scale = 3,Preprocessor = softedge_hed
これをさらにHires. fixで倍にアップスケール後。
| 元画像 | balanced | ControlNet is more important |
|---|---|---|

|

|

|
拡大してみるとわかるが、やはりbalancedの場合は線が甘く塗りの色が淡くなっているがControlNet is more importantにすると元の色に近づいて線もパキっとする。
ただ、線をあえて曖昧にしたり、塗りも薄めが良い場合もある。単純に絵の質感で言えば「好みの問題」と言えそうだ。
どちらにせよControlNet is more importantを使用することで「元画像の印象をプロンプトなしでも少しだけ再現」してくれるので、公式の解説にある通りいろいろな推定モデルを試してみる場合に使うと良いだろう。
ちなみにこの元画像は「トビラを開く魔法」としてchichi-puiに投稿した個人的にお気に入り作品。
リンク先にプロンプトなども掲載(再現はできないかも)
My prompt is more importantはいつ使う?
私の個人的な見解だがMy prompt is more importantにすると絵の書き込みが増える傾向があるように思う。
最近はとにかく細かく書き込まれた絵が好まれる傾向にあるので、まずは積極的に試してみると面白い。
Control Weight
どれぐらいControlNet側の画像を優先するかの値。
| 元画像(Depth) | 出力結果とWeightの値 |
|---|---|

|

|
Weightは大きく上げると線は再現されるかもしれないが、絵としての質が落ちる印象。上の結果からもそれが分かる。
基本はクオリティ重視で1がおすすめだが、ここを調整して使っているユーザーもよく見かける。
Starting/Ending Control Step
ControlNetの適用を途中から開始(Start) / 途中で適用を終了(End)するオプション。
v1.0時点でのテスト
| 元画像 | Starting=0(デフォ) | Starting=0.1 |
|---|---|---|

|

|

|
Starting = 0.1とすることでわずかにControlNetの適用開始が遅くなる。
つまり、Startingを遅らせたことによりAIが元絵にない背景が追加されている(右側の絵)
Endingはこれの逆で、1より低くすることで画像生成の途中でControlNetの画像が適用されなくなるもの。
あえて推定とは関係ない画像をAIに書かせたり、ControlNetの影響が強すぎて線が浮いてしまう場合等に使うと良さそうだ。
RGB to BGRはおそらく1.1で廃止
推定画像を別ソフトで作成した場合
推定画像(normalやdepth等)は別ソフトと互換性がある形式なので自前で用意できる(上級者)
ただし設定を理解しないまま各データを入れてしまうと想定外の動きをしてしまう。
なぜそうなるかというと
- 別ソフトで生成したマップ画像を
ControlNetに放り込む Preprocessorがオンになっていると放り込んだ推定画像から更に別の推定画像を生成する- 適用される推定画像がめちゃくちゃなため、結果もめちゃくちゃに
わかりにくいかもしれないが、自前でマップを用意する場合は(2)のPreprocessorをnoneにしてやらないといけない。
normal画像をBlenderで用意する例
わかりにくいと思うのでnormalを自前で用意する例で解説する。
まず、自作のノーマルマップをCGソフト(Blender)で生成する。
次にPreprocessorをNoneにしてModelをノーマルに設定する(重要)
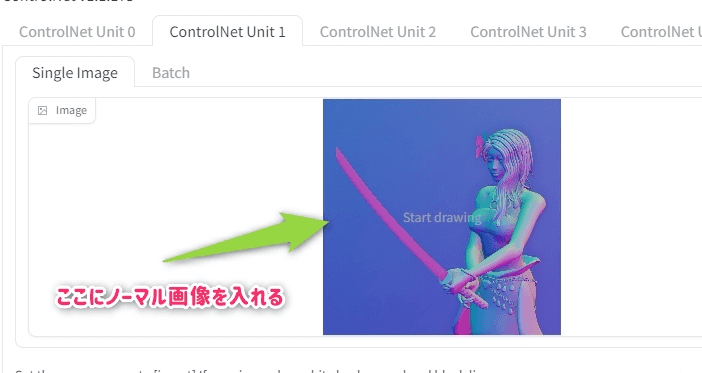

この状態で画像を生成してやれば良い。
| Blenderで用意したNormal画像 | 出力結果 |
|---|---|

|

|
同様の手順でDepthやLineartの他、openposeなどもBlender側で生成したマップを入れることができる。
BlenderでDepthを出力すると白黒が反対になるのでPreprocessorにInvertを指定すると良い。
CGソフトの使い方は別サイト参照。
複数のControlNetを同時に適用する
Settingsタブ > ControlNetの設定にあるMulti ControlNetの数値を上げると、上げた数値だけControlNetのUIが増えて、複数適用できる。

つまりDepth+Segmenetのような同時に複数のマップを利用して画像が生成できる。
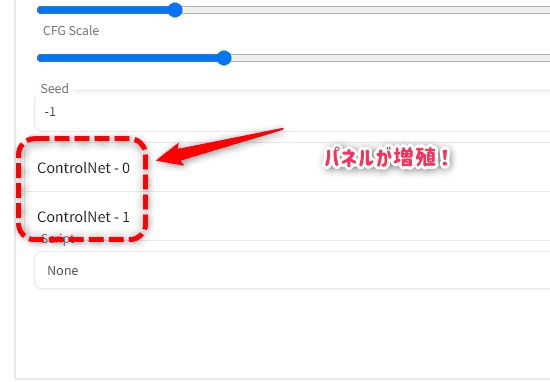
設定をApplyした後、UIの再読み込みではなくAutomatic1111本体から再起動する必要あり。
Multi-ControlNetの実用例
次のツイートよりtoyxyzさんが面白い使い方を提唱している。
By separately rendering the hand mesh depth and open pose bones and inputting them to Multi-ControlNet, various poses and character images can be generated while controlling the fingers more precisely. pic.twitter.com/Y4B3hYa9jd
— toyxyz (@toyxyz3) February 25, 2023
手とポーズを別々のControlNetで分けてやることで、今までAIが苦手だった手を正確に表現できることが発見されている。
toyxyzさんがBlenderにて画像生成用プロジェクトを配布してくれている。
Character bones that look like Openpose for blender _ Ver_4 Depth+Canny
テストしてみた
Multi-ControlNetを使って思い通りの画像を生成するテスト。
2023/04/21:この方法で作った画像を更新。どちらの画像も自作で用意したためこの方法はtoyxyzさんのツールは使っていない。
- 元画像をi2iに入れてそのままhed推定
- 手の補助用の画像を
Multi-ControlNet(2つ目)に入れてhed推定
| 元画像 | 手の補助 |
|---|---|

|
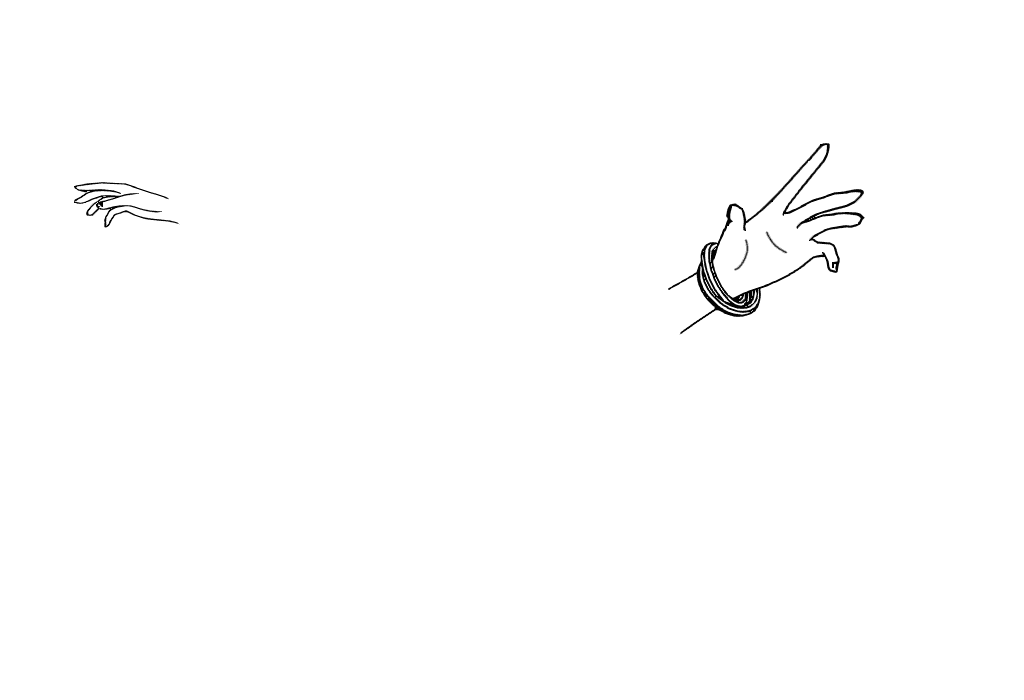
|
かなり簡略化しているが、基本は上のようなMulti-ControlNetを使って手指を再現する目的。
結果は次
個人的には大満足の結果となった。
推定画像も保存されてしまう(無駄な画像が保存される)
ControlNetを使用すると推定に使用する画像が自動生成されている(例:Lineartなら白黒の線画)
通常のイラスト生成であれば、これはファイルとしては保存されないがバッチ処理をする場合に保存されてしまう仕様のようだ。
そうなると出力ファイルを動画化する時に邪魔になる(v1.1.146時点)
これを保存しないようにできる。
上部のSettingタブ => 左側のタブからControlNet => Do not append detectmap to outputをチェック
最後に上部のApply settingsを押して保存。
これで生成された画像1枚だけの出力になる。
本来この機能はファイル保存に関する設定ではなく、生成結果(Generateボタンの下の画像が出るウィンドウ)に無駄な画像が表示されるのが嫌なユーザー向けだと思われる。
推定画像も保存する
デフォルトでマップ画像(Depthなどのグレースケール画像)は生成はされるがファイルには保存されない。
これを常に保存したい場合はSettingsよりAllow detectmap auto savingをオンにする。
Google Colabでのエラー
いくつかエラーがあったのでメモしておく
メモリ問題
Google Colabを使う時グラボではなくメインメモリがオーバーしてしまって落ちるという現象が多々あった。
またローカルで起動しても落ちることがよくある。
かなりメモリを消費している模様。
Stable Diffusion本体のモデルを変更しようとするとメモリがオーバーしてしまいよく落ちるので、こちらはUI起動後変更しないほうがよろしいかと思う。
Generate時にPythonエラー
Generateボタンを押した跡にコンソールにpythonのエラーが出ることがある。
これは殆どの場合Google Driveからpthファイルが正しくコピーされてなかったことが原因だった。
手動でドライブにファイルを格納して、同期完了となっていてもGoogle Colabからアクセスした場合に不完全なファイルとしてコピーされているのではないかと思われる。
ドライブにpthファイルを入れた場合は同期完了後5分ほど待ってから実行すると問題なかった。
他にもこのエクステンションに限ったことではないが画像サイズを大きくしていると止まってしまうことがある。
まずは512*512で試してみよう。
T2I adapter
ControlNetとは似て非なる技術にT2I adapterというものがある。
ControlNetとは違うものだがMikubillさんのwebuiではT2I adapterのモデルを読み込んで使用できる。
2023/05/13に全項目を再確認して編集
使用方法
通常の推定モデルと同じく、T2I Adapter専用のモデルをsd-webui-controlnet/models/に入れて利用する。
次が公式DL先
TencentARC/T2I-Adapter at main
しかし、どういうわけか私のケースだと動かないものがあるようなので有志が作っている別ファイルを使用。
各項目にリンク先を記載しておく。
t2ia_color_grid
公式のモデルがなぜかエラーで使用できないので有志?が生成しているモデルをDLする。
このときモデルとYAMLファイルの2つをDLしていないと動かないので注意。
ControlNet T2I-Adapter Models - T2I Adapter Color | Stable Diffusion Controlnet | Civitai
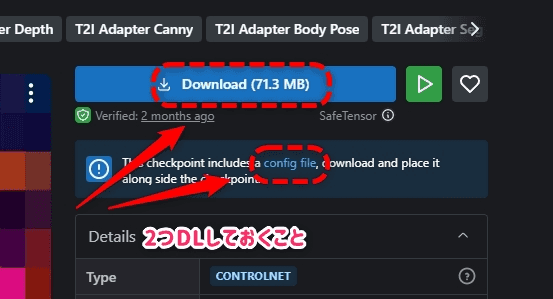
- Preprocessor :
t2ia_color_grid - Model :
controlnetT2IAdapter_t2iAdapterColor
入力された絵からカラー入りのモザイク画像を作成し、出力に反映させる。
モザイクの色のみならずピクセルの位置も反映されるようなので、元絵を一旦モザイク画像にしてi2iに通したような効果が得られるようだ。
| 元絵 | モザイクに変換 | 出力結果 |
|---|---|---|

|
|

|
正直なところ元絵のカラー情報を抽出して出力先に反映させるという使用用途だと思うが、微妙に元絵の構図に寄せたものが出てくるので使いにくい印象。
このあたりならより正確なinpaintやtileを使うか、もうすこしぐちゃぐちゃにして良いならshuffleが使える。
より実用的なケースは要調査。
t2ia_style_clipvision
こちらもモデルとYAMLファイルは次のサイトからDL(方法は上を参照)
ControlNet T2I-Adapter Models - T2I Adapter Style | Stable Diffusion Controlnet | Civitai
- Preprocessor :
t2ia_style_clipvision - Model :
controlnetT2IAdapter_t2iAdapterStyle
元絵の画風を反映させて新しい絵を作るモデル
ベースモデルを変更して、モデル越しに画風を受け渡すのが面白そう。
と思ったのだがあまりアグレッシヴな元絵だとベースモデルの限界は超えられない模様。
あくまで雰囲気だけ伝わるといった印象だった。
| 元絵 | モデル変更1 | モデル変更2 |
|---|---|---|

|

|

|
上の例では墨絵っぽいものが出るのかと期待したが、さすがにそれは期待しすぎのようだ。
ただ、雰囲気は明らかに継承しているので随時試していきたい。
t2ia_sketch_pidi
こちらもモデルとYAMLファイルは次のサイトからDL(方法は上を参照)
ControlNet T2I-Adapter Models - T2I Adapter Sketch | Stable Diffusion Controlnet | Civitai
- Preprocessor :
t2ia_sketch_pidi - Model :
controlnetT2IAdapter_Sketch
こちらはScribbleの亜種。ざっくりと書いたような線画に有用だと思われる。
推定画像はscribble_hedよりも書き込みが多くscribble_xdogよりも線が太いという絶妙な立ち位置。
| 元絵 | scribble_xdog | t2ia_sketch_pidi |
|---|---|---|

|

|

|
なのでModelをscribbleにしても正常に動く。
かなり微細な違いなので上級者向けといったところか。選択肢が増えた。
Tips
ControlNetのTips的な使い方を書いておく。
光と色味のコントロール
img2imgに光の元となる画像を入れて、ControlNetにメインのキャラクタのような画像を入れると

img2img側の色味や光源が反映されるので光のイメージをコントロールできそうだ。
| 作例1 | 作例2 |
|---|---|

|

|
Shuffleで複数キャラを描画
shuffleの項でも述べたが、キャラクターや動物のような画像をshuffleすると、そのキャラが複数人でてくるような動きをする。
とにかくたくさんのキャラを1つの画像に入れたい時にshuffleを使うと良いかもしれない。
ShuffleをNoneで使う
初音ミクのダンス動画を殆どチラつかせずにAI化に成功していたツワモノユーザーの設定を見ていた時にmodelをshuffle、Preprcessorをnoneにして使用していた。
おそらくだがt2iでControlNetを数珠つなぎにするときに一時的にi2iを挟むような効果がある。
ControlNetをかなり使い込んでいるとtileやinpaintもi2iに入れたような効果が有ることがわかるが、これらは元絵の色だけでなく線まで再現しにいく。
そこで、おそらく元絵の色情報だけを出力に反映させるような効果を狙っているのではないかと予想。
かなり上級者向け設定。
こちらは色のイメージは引き継ぐが、全く違うシーン、まったく違うキャラが出てくることも多い。
元絵とほぼ同じものがほしいが、若干の雰囲気や全体の色馴染みなどを調整する場合はinpaint(ControlNet)にマスクなしで使う。
より元絵のシーンやキャラのイメージを維持したまま別画像にしたい場合はreference-onlyを使うのが良い。
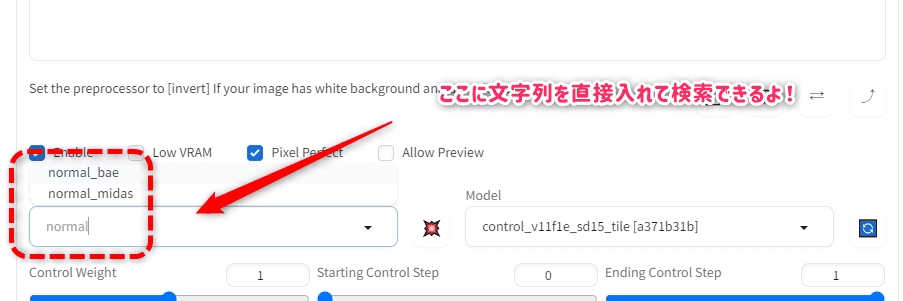
検索機能
PreprcessorやModelが多すぎてプルダウンメニューから選ぶのが面倒だ。
実はメニューの部分に直接文字列を打ち込めるので絞り込み検索ができる。
ControlNetの画像を「空のまま」で使う
i2iタブ側で画像を入れてControlNet側に何も画像を入れなければi2i側の画像がControlNetに入ったように振る舞う。
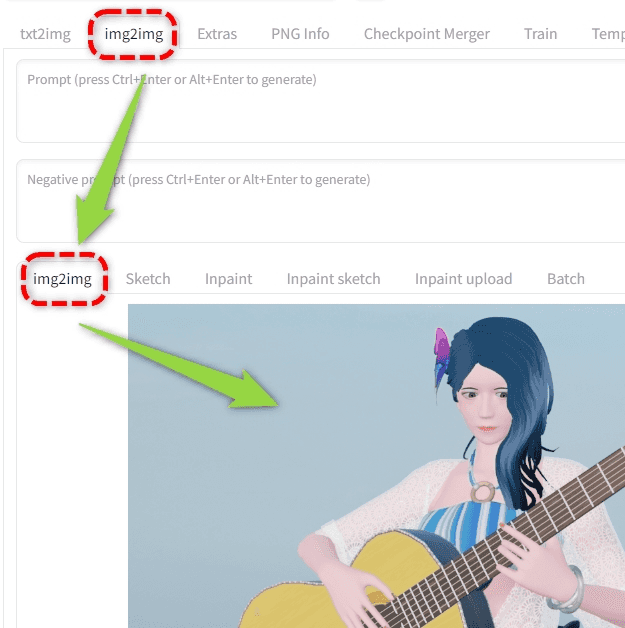

つまり上の例ではギターを引いているキャラクターの画像をControlNetに入れたのと同じ挙動となる。
もちろんPreprocessorやModelも自由に選んで良い。
これはいつ使う?
次の2つのケースで作業を効率化してくれる。
Multi-ControlNetを使っている時、全部のControlNetに一発で同じ画像を送りたい時i2i側のバッチを使いたい時(ControlNetのパネルでもできるがこちらの方が簡略的で早い)
動画化のテスト
動画化に関していろいろ実験しているので掲載する
ギターを弾かせる
ControlNet 1.1+EbSynthで動画化する例
動画化はチラツキをいかに無くすかが勝負。1.1でかなり一貫性がある絵が連続して出せるようになった。
特にAIは指の描画と物を持たせた絵が非常に苦手なのでそこに挑戦。
詳しくは次のツイートに記載
Blenderのジオメトリノードでリアルな動きを作る
ジオメトリノードで作った蝶(1.0で実験したものを1.1でブラッシュアップ, EbSynthなし)
Tileなど新しいものを採用。背景にHDRi, カメラを回転。
こちらはかなりチラついてしまっているが、個人的にはそれもまた味かと考えている。
Blenderのジオメトリノードの模様をAI化
これのi2i元となった動画は私のTwitterに掲載
元映像は次のBLOG記事で書いている方法を応用
Trim Curve(カーブトリム)を解説【Blender - Geometry Nodes】 | 謎の技術研究部
以下の実験はすべてv1.0時点(参考までに)
以下は1.0時点の研究。手法がすでに古いのでクオリティは下がるが参考までに。
Depth推定をつかった動画制作のテスト。
映像後半は使用したDepthの画像。
恐らくだがDepthは奥行きだけでなくシルエットを維持しやすいという特徴があるようで、活用方法がありそうだ。
こちらは蝶の作例。そもそもCGで私が自作アニメーションした蝶をベースにしているのでプロンプトの魔術は少なめでもいける。
こちらもDepthを使うことにより羽のシルエットを正確に捉え、アニメーションとして成立させるテスト。
背景を別で合成したほうが良いという知見や、撮影の角度によってはDepthであっても蝶の羽が消えてしまうなどの課題も見つかった。
Depthがシルエットを維持しやすいということは、模様を描かせるのが得意なのではという実験。
相変わらず背景のチラツキ課題はあるが、模様が入ったキューブが回転していることがハッキリと分かる。
後ろにも別の模様をいれているが、キューブ側の模様と後ろの模様が同一化するコマも多い。それもまた味とも捉えられる。
この場合はアナログノイズのような雰囲気も合わせてMVの1カットに十分使えそうに思える。
細かくスライスした3DCGをDepthにかけることで一貫性のあるアブストラクト動画にする例。
こちらもかなりMV風味。
CGで普通にレンダリングした人魚の画像をi2i側に入れて、自前で用意したSegment画像をControlNet側に入れて生成した動画例。
2枚の元画像を使った生成は現時点でバッチに対応していないので1コマずつ手作業で出力した。かなり大変。
上でも少し触れているが、この手法に限り指の再現度が極めて高い。
i2i1枚だけで処理した場合、Denoising=0.1にしても指の描画が壊れることを確認済み。
こちらの作例は手動で1枚ずつ出力したが1.1現在ではControlNetのバッチで自動対応可能。
さいごに
この記事は暫く更新を続ける予定。
ControlNetの登場でクリエーター側の意図をAIに伝えるすごいツールになりそう。
イラストが書けるユーザーであれば、線画だけ書いて色塗りを自動化できるのでかなり強力かも。
また、クリスタの3Dデッサン人形でポーズだけ作ってイラストを書かせるという手法を使っているユーザーもいて面白い。
今後は動画化などでも役に立ちそうなので暫く研究したい。
更新履歴
(06/16)mlsdの作例を追加した。3DCGアーティストが使うと非常に強力な可能性あり。最近作成した動画作例を新規追加。reference-onlyを読みやすく修正。Guess ModeのMy prompt is more importantについて追記。その他細かい修正。
(05/29)Control Typeが追加されたので使い方の項目を一新。referenseの追加された種類を追記。inpaint_onlyを追記。
(05/23)作例追加, 自作のmap画像とi2iを両方使う方法はControlNetのみで出来るため該当箇所を削除, i2iタブを使ってControlNet画像を空にする方法を修正してTipsへ移動, Normalの解説をわかりやすく修正, 誤字を修正
(05/15)reference-onlyを追加, tipsに検索機能の紹介を追加
(05/13)T2I Adapterを再調査, Tipsを追加
(05/09)一部過去の記事が残ってしまっていたので削除, Scribbleを読みやすく修正, Do Not Append...設定の箇所を読みやすく修正,
(05/07)Skip img2img processing when using img2img initial imageが廃止されたようなので該当部分を削除, Lineartの項目が抜けていたのでリンク追加, Normalを再テストして更新, 一部を読みやすく修正
(05/06)tile_resample追加
(04/30)threshold追加
(04/28)mediapipe_face,shuffle追加。Guess Modeを更新
(04/26)inpaint追加。
(04/23)scribbleを1.1に対応。Pixel Perfect,Allow Previewの機能を追加。その他改修。
(04/22)Guess Modeをv1.1で再テスト。その他読みやすく改修。
(04/21)Normal,openpose,segmentの項目を1.1に対応、その他読みやすく大幅に改修。
(04/19) hed,depth,mlsdの項目を1.1に対応、binaryを削除。


